
Why E-Commerce Apps Are So Hard to Reverse Engineering and Scrape
E-commerce giants in Asia such as Shopee, Lazada, Tokopedia, Temu and others have developed some of the most advanced anti scraping and anti automation mechanisms in the world. Unlike traditional web applications where you can simply monitor network traffic in a browser and replay the requests, these mobile first platforms are designed with layers of protection, including:
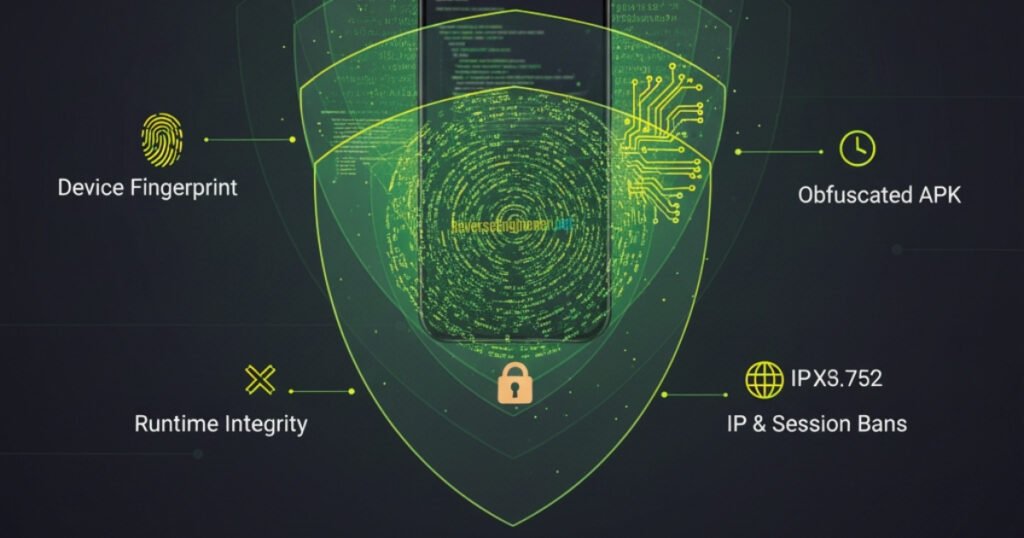
- Reverse Engineering Encrypted API requests and responses (using custom symmetric/asymmetric crypto inside native
.solibraries). - Dynamic tokens tied to device fingerprints (user-agent, device model, OS version, emulator detection).
- Obfuscated APK code (heavily protected classes, methods, and JNI bridges).
- Runtime integrity checks to block modified apps or hooked processes.
- IP, proxy, and session-based bans that can trigger after only a few dozen requests.
- Captchas and bot detection triggered by unusual traffic patterns.
These protections serve two goals:
- To ensure the platform’s data exclusivity (so competitors cannot mass-harvest product data).
- To prevent fraud, abuse, and arbitrage bots that exploit pricing and promotions.
For businesses, researchers, and competitive intelligence teams, however, accessing this data is essential. That’s where reverse engineering comes in. At ReverseEngineer.net, we specialize in overcoming these barriers through responsible, legally-compliant reverse engineering, giving our clients controlled, scalable access to e-commerce APIs.
Case Study: Reverse Engineering the Temu App
Temu is a flagship example of a highly protected e-commerce mobile app. Its API endpoints are not publicly documented, and many critical ones for product details require complex tokens and headers that change dynamically.
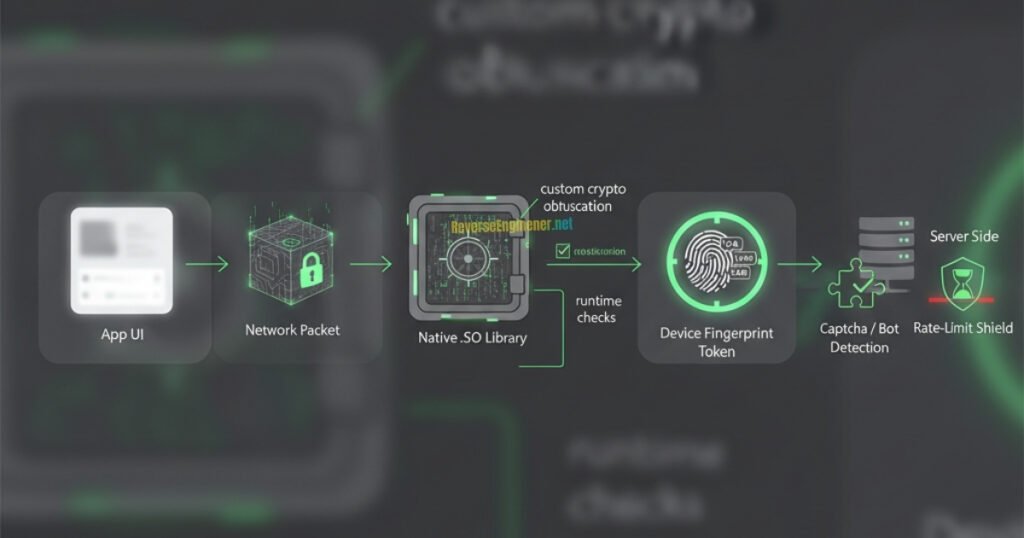
Step 1: Static Analysis of APK and Native Libraries
The process begins with APK decompilation and inspection of .so libraries. Temu’s native libraries handle much of the token signing logic. By loading the binary into Ghidra or IDA Pro, we identify:
- Key cryptographic routines (AES, RSA, SHA variants).
- JNI functions called by Java to request signed headers.
- Obfuscation layers and anti-debugging traps.
This stage provides the map of where tokens are generated and what parameters (timestamps, device IDs, user-agent strings) are used as inputs.
Step 2: Dynamic Analysis with Frida
Static analysis only shows part of the story. To see real token generation in action, we inject Frida hooks into the app running in an emulator or rooted device. By attaching to methods inside .so libraries, we can:
- Intercept header generation functions (
af-ac-enc-dat,x-sap-ri,af-ac-enc-sz-token). - Capture inputs and outputs of crypto functions.
- Monitor runtime environment checks (emulator detection, root detection, certificate pinning).
Frida allows us to bypass Temu’s anti-debugging defenses and obtain live, valid tokens in real time.
Step 3: Overcoming Environment Bindings
One of the most surprising discoveries during Temu research was that some tokens are bound to environment fingerprints. For example:
- User-Agent strings (browser version, OS, device model).
- Device identifiers (IMEI, Android ID, virtual machine markers).
- Execution environment (emulator vs. physical phone).
If a token generated in one environment is reused elsewhere, Temu can easily detect the mismatch and block the request.
To overcome this, we implemented two strategies:
- Node.js bridge for dynamic header generation – API requests from Python are routed through a Node.js layer that mimics a real environment, ensuring generated tokens remain valid.
- Frida runtime extraction – Instead of replicating token generation externally, we capture the exact headers from the app itself as it runs. This guarantees 100% validity.
Step 4: Network and Proxy Management
Even with valid tokens, Temu actively monitors traffic patterns. We observed:
- After ~70 consecutive requests from the same IP, bans or captchas begin.
- Residential proxies and mobile proxies are tolerated much longer.
- Session stickiness (keeping the same IP for cookie generation and requests) improves reliability.
We tested various strategies:
- Sticky sessions with residential proxies.
- Mobile carrier IP rotation via API triggers.
- Custom VPN orchestration with persistent tunnels.
The conclusion: proxy diversity and cookie rotation are just as important as token generation.
Step 5: Scaling and Automation
Finally, for scale (e.g., 1,000,000+ product pages/day), we built infrastructure that:
- Rotates cookies obtained via background Temu sessions.
- Uses debug tokens to bypass the need for constant regeneration.
- Orchestrates requests across distributed IPs with cooldowns and smart retry logic.
This allows large-scale scraping while minimizing bans and avoiding detection.
A General Framework for Reverse Engineering E-Commerce Apps
While Temu is a prime example, the same challenges exist across multiple platforms:
- Shopee: Similar
.sotoken generators, with RSA-signed headers. - Tokopedia: Encrypted GraphQL requests with rolling keys.
- Amazon App: Device binding and encrypted product detail endpoints.
- Alibaba/Aliexpress: Strong obfuscation and anti-Frida traps.
Our general methodology remains the same:
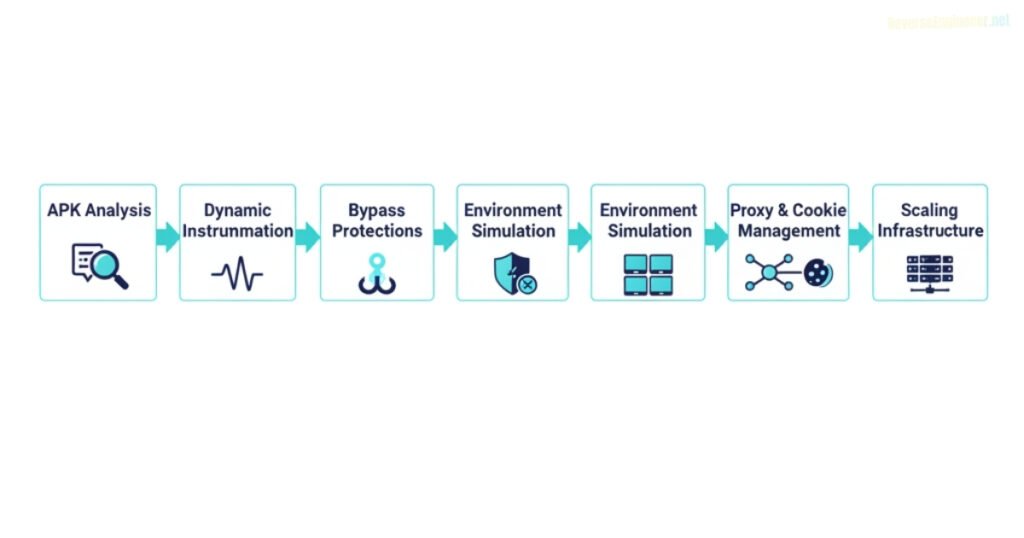
- APK Reverse Engineering: Identify crypto and signature logic.
- Dynamic Instrumentation: Hook into runtime with Frida or Xposed.
- Bypass Protections: Anti-root, anti-emulator, SSL pinning, obfuscation.
- Environment Simulation: Create realistic device fingerprints.
- Proxy & Cookie Management: Ensure traffic flows naturally.
- Scaling Infrastructure: Automate, rotate, distribute requests.
Common Technical Challenges and Our Solutions
Many customers ask us, “Why can’t I solve Shopee, Lazada, AliExpress, Amazon app APIs, or similar e-commerce applications myself?”
The answer is simple: these systems are specifically designed to be “uncopyable, unbreakable, and untraceable.” Our job is to find ways to penetrate these invisible walls. Below, I’ll explain some of the critical technical challenges we encounter in such projects. However, I won’t fully cover the solutions, as this is where the real know-how and value lies.
Symmetric and Asymmetric Encryption Layers
Modern mobile applications use multiple layers of encryption simultaneously. You’ll typically see a combination of AES (sym) + RSA/ECC (asym). But it’s often more than that; custom variants are combined with their own custom padding mechanisms and base obfuscations.
The Problem: Header tokens or request body data are encrypted uniquely for each request. Copying a token won’t work, as it becomes invalid after 2 seconds.
Tip: To break these layers, we don’t just need to “know the encryption algorithm.” The real challenge is to capture the right moment in the application’s memory and penetrate that encryption chain.
Intensive Obfuscation and Virtualization
Well-known obfuscators like DexGuard, Jiagu, and ProGuard now seem simple. In Asian-based applications, you’ll often see custom-written obfuscators and native-VM (virtual machine)-based code protection.
The problem: Every function in the code is hidden under fake names, control flow is constantly changed, and static analysis becomes nearly impossible.
Tip: The solution isn’t just using Ghidra/IDA Pro. Sometimes we use our own scripts, sometimes custom deobfuscation engines. The trick is to extract the real signature algorithm from the mass of fake code.
Emulator and Root Detection
Nearly all major applications include emulator detection mechanisms and root/jailbreak checks. These check IMEI, CPU, sensor data, memory maps… The list goes on.
The Problem: If you fail these checks, the application either crashes or returns different, “empty” API responses.
Tip: Simple “ro.build” string modifications aren’t enough. We build advanced environments that mimic real user behavior.
Cookie and Fingerprint Binding
Many applications bind cookies to the IP address, the device, or even the User-Agent string. This means the same cookie will be invalid if used from a different IP address. Worse, a unique fingerprint is generated for each device, and all requests are checked accordingly.
The Problem: This mechanism defeats the classic “cookie jar + proxy rotation” tactics.
Tip: The proxy isn’t the only issue here. It’s necessary to understand the actual “session fingerprint.” Our job is to figure out how that fingerprint is generated and what parameters it consists of.
CAPTCHA and Behavioral Obstacles
CAPTCHAs are no longer just visual; they’re also behavioral. When you send too many requests, speed, sequence, and timing analyses are performed. The system checks whether this user is real or a bot.
The problem: Simple automated solvers only yield 50% success.
Tip: We try different layers for CAPTCHA bypassing: sometimes an ML-based solver, sometimes “backdoor” parameters. The method used depends entirely on the target platform and the customer’s needs.
Dynamic .so Libraries
Almost all Asian-based applications embed critical signature generation in their native .so libraries. These libraries change with each release, and “booby trap” checks are constantly added.
The problem: The hook you run in one version may be broken in an update a week later.
Tip: Our approach is to set up a “dynamic analysis pipeline” that doesn’t rely on a single version, so the same method can be automatically adapted when updates arrive.
The Business Impact of Reverse Engineering E-Commerce Apps
Reverse engineering ecommerce platforms like Shopee, Temu, or Lazada isn’t just about solving a technical puzzle. These projects have a direct and measurable business impact by transforming how companies compete and operate in digital marketplaces.
Our advanced data collection and scraping solutions give businesses real-time access to competitors’ pricing, promotions, discount strategies, and inventory levels. This enables smarter pricing decisions, faster response to market changes, and optimized product positioning. Without this layer of competitive intelligence, companies operate in the dark while their competitors adapt on the fly.
Reverse engineering enables automated tracking of product catalogs across thousands of SKUs. Instead of relying on manual checks, businesses can track new arrivals, stock fluctuations, and category expansions at scale. This automation not only saves time but also ensures marketing and supply chain teams always have up-to-date information.
Another key benefit is that in regions where fake and fraudulent listings are common, reverse engineering becomes a fraud prevention weapon. By systematically scanning product pages and API calls, businesses can identify fake listings, price manipulation, or abusive seller behavior before they damage brand reputation or customer trust.
In short: Without reverse engineering, companies remain blind to these insights. Through reverse engineering, they gain a competitive advantage: the ability to see beyond the surface of e-commerce platforms, automate intelligence gathering, and stay ahead of both competitors and fraudsters.

Conclusion: Why Work With ReverseEngineer.net
At ReverseEngineer.net, we bring together years of expertise in:
- Mobile app reverse engineering (Android/iOS).
- Cryptographic system analysis (AES, RSA, custom schemes).
- Scaling automation infrastructures (requests/day scraping pipelines).
We’ve successfully helped businesses bypass complex anti scraping systems with robust, future-proof, and scalable solutions If you’re facing similar challenges whether any other app get in touch today. Let’s build a solution that not only works now, but keeps working tomorrow.
Let's Work Together
Need Professional Assistance with Reverse Engineering or Cybersecurity Solutions? Our Team is Ready To Help You Tackle Complex Technical Challenges.