
Financial Data Feed Protocols are the lifeblood of trading systems, delivering real-time quotes and trades in high volume. Because many of these feeds use proprietary, undocumented protocols, accessing the raw data on your own terms requires reverse engineering. As one expert quipped, obtaining detailed intraday market data often takes “A bit of work and Wireshark” meaning engineers must capture and analyze network traffic to decode how a feed works. In a previous article, we discussed foundational methods for decoding a UDP-based financial data feed. Now, we will delve into advanced reverse engineering techniques; PCAP analysis, live traffic reverse engineering, data integrity validation, and protocol fuzzing that are commonly used to dissect proprietary market data feed protocols. These techniques form a cohesive workflow for turning opaque binary streams into meaningful information.
PCAP Analysis and Binary Extraction from Captures
One of the first steps in decoding an unknown market data protocol is to collect example data. PCAP analysis refers to inspecting packet capture files (PCAPs) of the feed’s network traffic. By capturing a feed’s UDP packets using tools like Wireshark or tcpdump, an engineer obtains a record of the raw binary messages. Analyzing these captures offline is invaluable: it allows careful, repeatable examination of message contents byte by byte. Often, the raw feed data looks like gibberish in a hex editor. The goal is to extract those bytes and identify structure within them.
Binary extraction from PCAPs is an important technique. Rather than only viewing packets in a sniffer GUI, reverse engineers will often export the raw payload bytes for deeper analysis. For example, Wireshark lets you follow a UDP stream and save its data as a binary file. With the feed bytes saved, you can load them into a hex dump tool or write scripts to parse them. This extraction process is crucial for handling proprietary feed protocols it frees the data from the capture format so you can apply custom analysis. One case study described how engineers isolated a stock feed’s binary responses containing price history by recording a clean PCAP sample and then examining the data offline. By working with the binary directly, you can start spotting patterns that hint at fields or encoding.
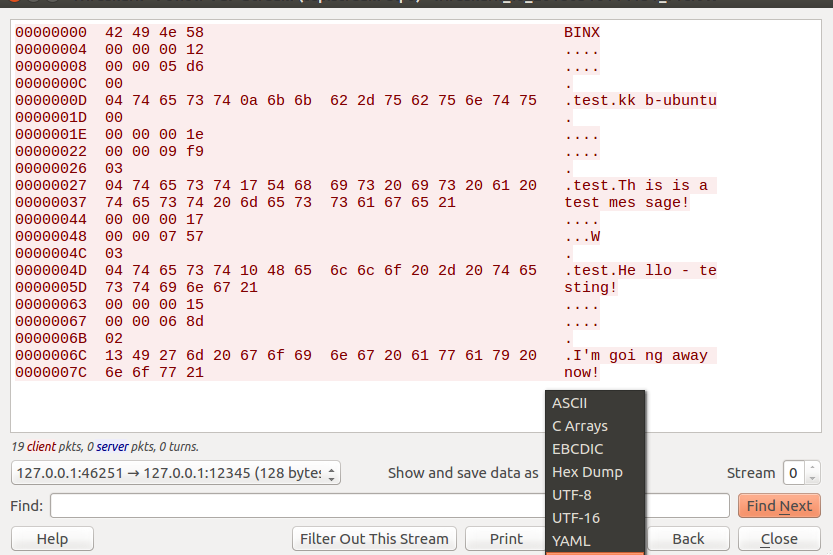
When analyzing PCAP data, look for any recognizable patterns or markers in the bytes. Proprietary financial protocols may not be human-readable, but they often aren’t completely random. There might be magic bytes or constant headers present. For instance, in one feed capture the first four bytes formed a distinct ASCII string that served as an identifier (a form of magic number), immediately signaling the start of each message. In another real case, the only readable part of a binary blob was the text “N^GOOG“, corresponding to a stock ticker, amidst otherwise gibberish data. Finding such anchors gives clues about the message structure in this case, it told engineers that symbols were embedded in the stream, and that other fields (like prices or timestamps) must be encoded around that area. Additionally, comparing multiple packets can reveal fixed vs. variable parts. If certain bytes stay the same across all captured messages, they likely form a static header or constant fields. One reverse engineering study found that every UDP packet in a feed was the same length, with the first ~15 bytes identical each time. This strongly suggested a fixed header containing things like a message type, protocol version, or length field. By recognizing those constant bytes and their position, you delineate the boundaries of the protocol’s frame structure. In summary, PCAP analysis provides the raw data needed to begin deciphering a feed, and by extracting and scrutinizing the binary contents for patterns, you build the foundation for understanding the protocol.
Live Traffic Reverse Engineering and Packet Inspection

While offline PCAP analysis is powerful, it is often complemented by live traffic reverse engineering – analyzing the feed in real time as data flows through a running system. Live analysis involves capturing and inspecting network packets on the fly, which can provide additional insights that static captures might miss. For example, observing the feed live makes it easier to correlate specific external events with packet contents. If you know a significant market event occurred at a certain time, you can watch the live packets around that moment to see how the feed encodes that event. This real-time correlation can confirm which fields correspond to prices, volumes, or timestamps based on their changing values.
Live packet inspection is typically done with the same tools as PCAP capture, just used interactively. An engineer might run the vendor’s feed client software on a machine and simultaneously sniff the network interface using Wireshark or a custom packet logger. By doing so, you can literally watch the feed’s packets as they arrive. The advantage of this dynamic analysis is twofold: first, it helps ensure you’re capturing everything (some protocols might have handshake or login messages at startup that you could miss if you only had a truncated capture). Second, it allows for quick sanity checks of your understanding – if you think a certain byte represents, say, the number of active orders, you can watch that byte in live traffic as market conditions change to see if it behaves accordingly. Live reverse engineering also helps in identifying timing-related aspects of the protocol. Many market feeds send heartbeat messages or sequence resets at regular intervals. By inspecting packets in real time, you’ll notice these periodic messages and can distinguish them from data-carrying packets.
In practice, live traffic analysis is often used in combination with the official client software. Since the feed is proprietary, you may not have a ready-made parser – but you do have the vendor’s application which is receiving and decoding the feed for display. Treating that application as a black box, you can intercept what it receives over the network. For instance, running the feed client and sniffing its inbound packets shows you the raw data before the client’s software logic processes it. If the feed uses encryption or compression, observing the live traffic alongside the client’s outputs (such as the prices it displays) can reveal the transformation steps needed to decode the data. Essentially, live packet inspection provides a real-time window into the protocol’s operation, which is invaluable for reverse engineering time-sensitive financial feeds. It complements offline PCAP analysis by validating hypotheses and uncovering any dynamic behaviors (like sequence number increments or keep-alive messages) that might not be obvious from a static snapshot.
Data Integrity Validation: Checksums and Magic Bytes

Decoding a market data protocol isn’t just about parsing fields; it’s also about ensuring you’ve interpreted the structure correctly. Proprietary feeds often include built-in data integrity validation mechanisms that you can use as clues in reverse engineering. Two common integrity features are checksums and magic bytes.
Checksums are error-detecting codes added to messages to verify that the data wasn’t corrupted in transit. In many UDP-based financial feeds, the protocol implements its own checksum or CRC (cyclic redundancy check) because UDP itself has no delivery guarantees. As you dissect the binary format, watch for a field that consistently changes in a way unrelated to prices or sequence numbers – this could be a checksum. For example, you might find that the last two bytes of each message vary unpredictably even when other fields repeat, hinting that those bytes encode a checksum of the preceding data. To confirm, you can attempt to compute common checksums (16-bit CRCs, XORs, simple additive sums) over the message and see if any match the value in the packet. Once you identify a checksum algorithm, it becomes a powerful validation tool: if your reimplementation of the protocol can reproduce the checksum correctly, you know you’ve likely parsed the message structure right. Moreover, understanding checksums is critical for building any client or decoder – you will need to generate valid checksums for the feed to accept your messages (in protocols where clients send data) or to verify incoming data integrity.
Magic bytes (or magic numbers) are another integrity and identification feature. These are fixed byte sequences placed typically at the start of a packet or message to mark it as belonging to a specific protocol. If you notice a constant sequence like 0x42 0x49 0x4E 0x58 (“BINX” in ASCII, for example) at the beginning of all messages, that’s a magic signature indicating the protocol type or version. Magic bytes help both the original software and the reverse engineer align to message boundaries – they act like a beacon saying “a new message starts here.” When decoding an unknown feed, finding a magic constant greatly simplifies the task of framing the data. It also provides a sanity check: any deviation from the expected magic value likely means either a parsing mistake or a truly malformed packet. Thus, as you parse captures, always verify if there are expected constants (magic values, protocol version numbers, etc.) in place. Their presence confirms you haven’t become misaligned in reading the binary data.
Beyond checksums and magic bytes, proprietary feeds include other data integrity mechanisms like sequence numbers and heartbeats. Sequence numbers increment with each message to ensure no data is missed; if there’s a gap, the client knows packets were lost. From a reverse engineering perspective, sequence fields are usually obvious once identified – they increase steadily and reset at known intervals (e.g. daily or when the feed reconnects). Confirming the sequence numbering in your captured data is a form of integrity validation: if the sequence jumps unexpectedly, you may have missed capturing some packets or mis-parsed a message boundary. Heartbeat or keep-alive messages, which often contain no data other than perhaps a timestamp or sequence ID, also serve to assure integrity by indicating the feed is alive even when no market events are happening. Recognizing these can prevent you from misinterpreting heartbeats as data-bearing packets. In summary, paying attention to integrity fields – checksums that verify content, magic bytes that delineate messages, sequence numbers that track order – not only helps you reverse engineer the protocol correctly but is essential for building a reliable decoder that can handle real-world feed data without errors.
Protocol Fuzzing to Uncover Hidden Structures

Once you have a working understanding of a feed protocol’s basic structure, you can push your analysis further with protocol fuzzing. Fuzzing is a technique where you send deliberately varied or even random data through a system to see how it responds. In the context of reverse engineering a market data feed, protocol fuzzing can uncover hidden message types, optional fields, or validation rules that aren’t immediately obvious from passively observing the feed. Essentially, you are actively probing the protocol for weaknesses or undiscovered behaviors, much like a security researcher fuzzing for vulnerabilities – except here the goal is to illuminate the protocol’s design.
There are a couple of ways fuzzing comes into play for proprietary feeds. One approach is to fuzz the client side: if you have access to the official client software (which parses the feed), you can create a dummy server that sends malformed or modified packets to that client. By observing what causes the client to error out or how it reacts, you learn about the protocol’s expectations. For instance, you might insert extra bytes in a message or alter a field to an out-of-range value; if the client disconnects or logs an error upon receiving such data, it tells you that you violated some assumed structure. This can reveal the existence of length fields, field size limits, or unknown flags (for example, flipping a bit in a flags field might toggle a feature in the client). Another approach is fuzzing the server side (if you can connect to the real feed source or a test harness) by sending your own crafted subscribe requests or other interactions, though often market data feeds are one-way broadcasts with limited client commands. Still, even in one-way scenarios, you can fuzz by creating variations of recorded packets and seeing if the client accepts them. If a slightly altered packet is ignored by the official client, you’ve likely tripped an internal consistency check (perhaps a checksum failure or an invalid message type), indicating what kind of validations are in place.
Modern tools can assist with protocol fuzzing. For example, the open-source framework Netzob allows testers to model an inferred protocol and then generate test cases to fuzz it. This kind of generation-based fuzzing uses your reverse-engineered knowledge of the message format to produce new message variants systematically. By defining the fields (and their possible values) that you’ve discovered, you can have the fuzzer permute through combinations or introduce random mutations in a controlled way. Netzob and similar tools consider the protocol’s state machine and field structures to create optimized fuzz cases, which is more effective than sending completely random data. In our context, an optimized fuzzer might, for example, vary the length field of a message to be inconsistent with the actual data length and observe if the client detects this mismatch – thereby confirming the role of that length field. Or it might try random values in the message type field to see if any undocumented message formats trigger a different behavior in the client (perhaps the client silently supports a message type not seen in the normal feed, which your fuzzing could expose).
Protocol fuzzing is an advanced step because it requires a test harness or environment where you can safely experiment on the feed protocol. However, it completes the reverse engineering workflow by proactively validating your findings. If passive analysis mapped out the protocol’s visible structure, active fuzzing helps ensure there are no blind spots no hidden checksum you missed, no special command message that only appears under certain conditions, and no parsing rule that isn’t covered by your current understanding. In addition, fuzzing has the side benefit of potentially finding security weaknesses (buffer overflows, etc.) in the feed’s implementation, which is important if your goal includes assessing the robustness of the system. By uncovering how the protocol breaks (or holds up) under invalid input, you ultimately gain confidence that you have truly mastered the format.
Integrating Techniques into a Cohesive Workflow

Each of the techniques above PCAP analysis, live traffic inspection, integrity validation, and fuzzing – contributes a vital piece to the reverse engineering puzzle. In practice, they are not isolated steps but parts of an iterative workflow for decoding a proprietary market data protocol. A typical engagement might begin with PCAP capture and analysis: gather sample data, identify obvious patterns (magic bytes, fixed headers, clear text fragments), and make an initial guess at the message structure. Next, you move to live traffic reverse engineering to verify those guesses in real time, ensuring you correctly interpret sequence increments or timing-related messages. Live analysis also helps capture any setup or handshake exchanges that a static PCAP might have missed, thereby rounding out the picture of how the feed initializes and maintains its data stream.
Once a draft understanding of the protocol is in hand, you apply data integrity checks as a confirmation mechanism. For example, if you think you’ve found a length field and a checksum, you recalc lengths and checksums from your parsed data to see if they match the values in the packets. This step acts as a reality check – any mismatch means your field definitions might be wrong. By iterating between refining the parse and validating with integrity fields, you converge on a consistent interpretation of the protocol. Finally, armed with this knowledge, you perform protocol fuzzing as a stress-test of your reverse-engineered spec. Fuzzing can be seen as the last mile of the workflow: it forces the protocol (or its implementation) to reveal any hidden quirks. If your understanding is correct, the system’s behavior under fuzzing will be predictable (e.g. it rejects bad inputs gracefully, and you know why). If the fuzzing uncovers surprises – say an unexpected message type doesn’t cause an error that could indicate there’s more to discover (maybe an undocumented message that the client handles). You then loop back, incorporating that insight into your protocol model.
By combining these advanced techniques, reverse engineers can systematically crack even the most complex financial feed protocols. What starts as an unreadable stream of bytes turns into a well-documented message specification through this workflow. The end result is typically a custom decoder or parser you build, which can plug directly into trading systems or analytics platforms, freeing you from the vendor’s black-box software. At ReverseEngineer.net, we specialize in using these techniques to help clients unlock their market data. Our experts have reverse engineered numerous proprietary feeds by meticulously analyzing PCAPs, intercepting live traffic, validating every checksum and sequence number, and even fuzz-testing protocols for edge cases. This comprehensive approach ensures that nothing is left unknown – giving our clients full control over previously opaque data streams. In the fast-paced world of finance, such reverse engineering work turns secret data formats into transparent ones, empowering firms to integrate and utilize market data in innovative ways. With a methodical workflow and the right tools, even undocumented financial data feed protocols can be decoded and understood, opening up a world of possibilities beyond the confines of the original vendor’s software.
Let's Work Together
Need Professional Assistance with Reverse Engineering or Cybersecurity Solutions? Our Team is Ready To Help You Tackle Complex Technical Challenges.